Let’s start with some basics. Just like when you want to talk to another person, you talk in a language that both of you understand, every system that wants to talk to another system needs to talk in a commonly understood language. Technically, we call it a protocol. HTTPS is a protocol, and so is English. Every protocol is designed with some goals in mind. For real-world languages, the goals are simple. They are usually communication, literature and so on. With computer protocols, the goals have to be more stringent. Usually, different computer protocols have very different purposes. For example, File Transfer Protocol (FTP) was (and still is) widely used for transferring files, Secure Shell (SSH) is used for remote administration and so on.
Note that we’re only talking about application layer protocols in the Internet Protocol Suite. Once the appropriate protocol in the application layer creates a packet for transmission, this is encapsulated in many coverings, one by one, by all the layers beneath it. Each layer attaches its own header to the message, which then becomes the message for the next layer to attach its header on. A reverse of this process happens on the recipient’s end. It is easier to imagine this process as peeling of layers of an onion.
So having that set, we’ll start out discussion about HTTPS. HTTPS, or HTTP Secure, is an application layer protocol that provides HTTP traffic encryption using TLS (Transport Layer Security) or its predecessor, SSL. The underlying application doesn’t have to worry about HTTP or HTTPS, and once the initial handshake is done, for the most part, it is just an HTTP connection, one that is over a secure tunnel. I’ve been a frontend engineer and I’ve never written any specific HTTPS code, ever. That’s the magic of TLS.
What’s TLS?
So HTTP that is encrypted using TLS is HTTPS. Got it. But what about TLS then? For starters, TLS is a hybrid cryptosystem. It uses multiple cryptographic primitives underneath its hood to achieve its goals.
Aside on cryptographic primitives: Cryptographic primitives, like symmetric encryption, block ciphers and so on are designed by experts who know what they’re doing. The role of protocol implementers is to take these primitives and combine them in useful ways to accomplish certain goals.
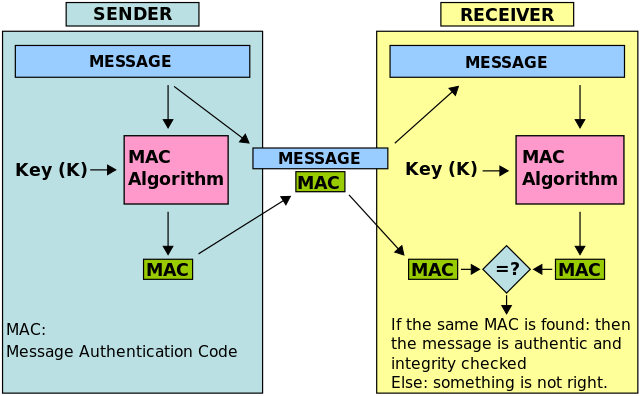
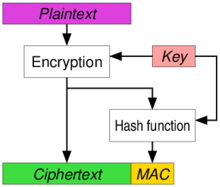
TLS uses symmetric key encryption, asymmetric key encryption, and (sometimes) message authentication code to establish an encrypted bidirectional data tunnel and transfer encrypted bits. We’ll try to explore how each primitive is used to attain some goal in a bit. With these primitives, particularly with public key infrastructure (PKI), TLS establishes the identity of one or both the parties involved in a communication (your browser and the web server in most cases). Then, a key is derived at both the ends using another primitive called Diffie Hellman or RSA which are asymmetric key crypto algorithms. Once the key is derived, this key can be used as the session key to be used in symmetric key algorithms like AES. If an authenticated encryption mode is not used (such as GCM), then a MAC algorithm might also be needed (such as HMAC). Also, a hashing algorithm (such as SHA256) is used to authenticate the initial handshake (and as a PRF if HMAC is used). Let’s try to follow a typical HTTPS handshake and see what we learn during it.
In the beginning…
In the beginning, there was no connection. You open your browser and type in nagekar.com. The following things will happen in that order, more or less.
- Your browser send a DNS resolution request for nagekar.com.
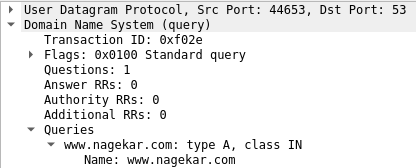
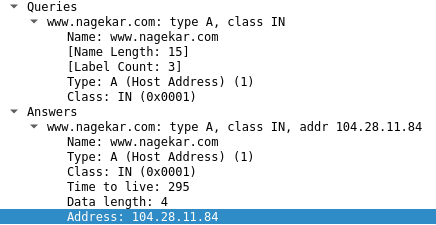
- Your router (or any DNS resolution service) will provide you with the IP address of the host
- Now the three way TCP handshake that we studied in our networking classes happen (SYN -> SYN/ACK -> ACK).

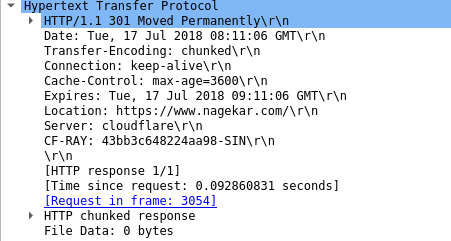
- After establishing a TCP connection, your browser makes a request to 104.28.11.84 for host nagekar.com. The server responds with a 301 Moved Permanently as my website is only accessible over HTTPS and with the WWW subdomain.
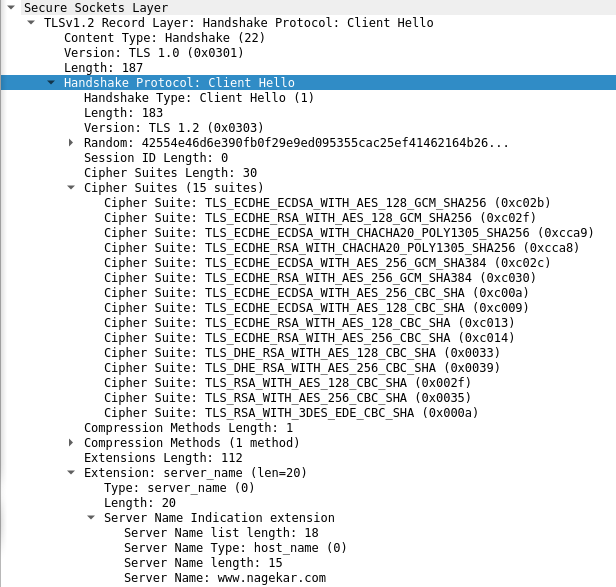
- Now starts the TLS handshake. First client sends a client hello. It contains the following important pieces of data:
- A random 28 byte string (later used for establishing session key).
- Session ID (used for resuming a previously established session and avoiding the entire handshake altogether, 0 here because no previous sessions found).
- Cipher suites supported by the client in order of preference.
- Server name (this enables the server to identify which site’s certificate to offer to the client in case multiple websites are hosted from a single IP address, as in the case with most small/medium websites).
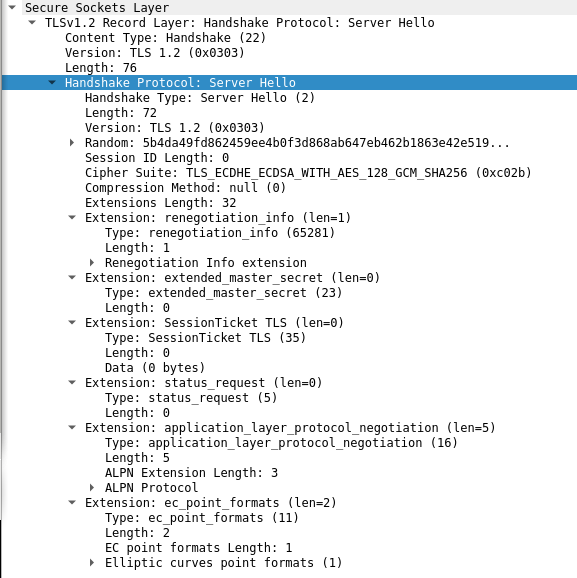
- Then server sends a server hello which has the following important pieces of data:
- Another random 28 byte string (later used for establishing session key)
- Cipher suite selected by server (in our case, the server selected TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 which was our most preferred cipher suite)
- At this point, both client and server have the necessary information to establish an encrypted tunnel, but one important detail is missing. No party has verified the identity of the other party (and if not done, it really defeats the purpose of whatever came before this since an active man-in-the-middle adversary could easily break this scheme). This is done in the certificate message. In most cases, only the client will verify the identity of the server. Here’s how it looks like:
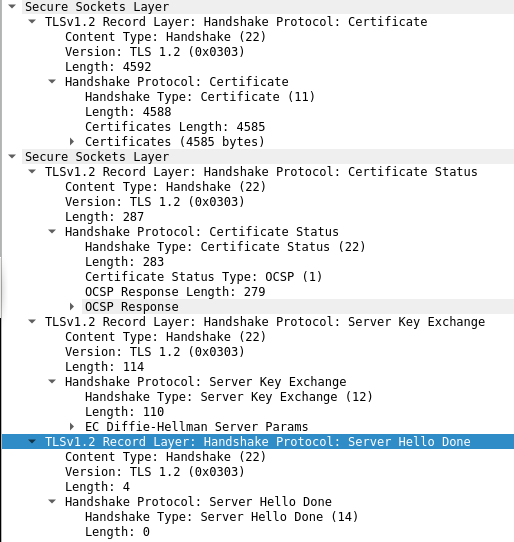
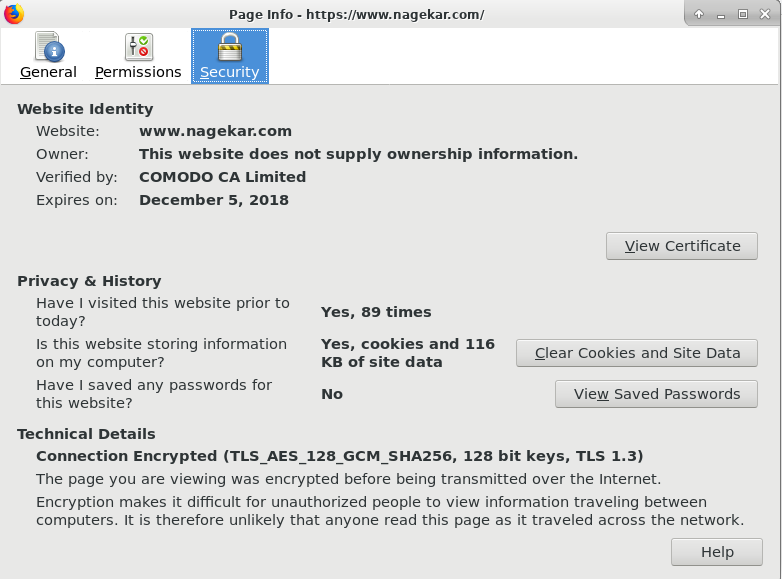
- And this is exactly what you see when you click on the green padlock icon in your address bar and try to see more information about the certificate offered by the website.
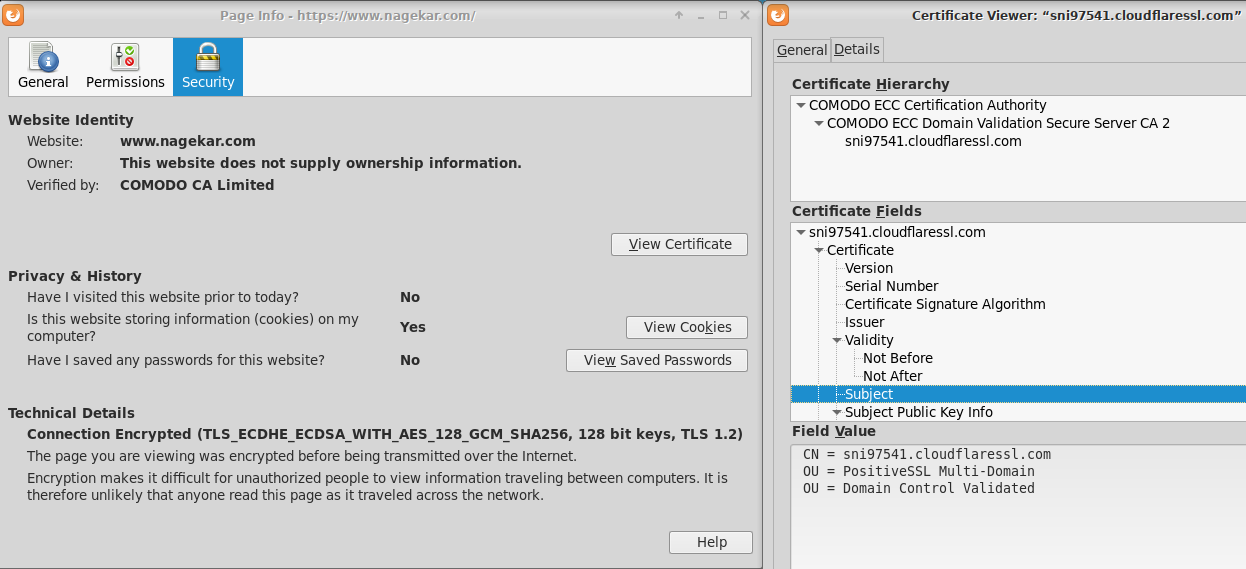
- At this point, the server hello is done. It is indicated in the message that the server won’t be asking the client for a certificate.
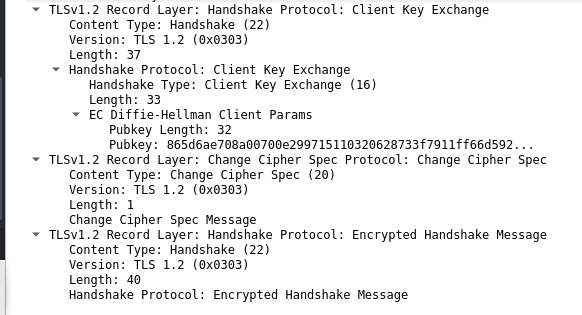
- The server sends one half of the Diffie Hellman key in a separate Server Key Exchange message. Following this, the client sends other half of the Diffie Hellman key exchange. After that, the client sends a Change Cipher Spec message which means any subsequent message from the client will be encrypted with the schemes just negotiated. Lastly, the client sends the first encrypted message, an encrypted handshake.
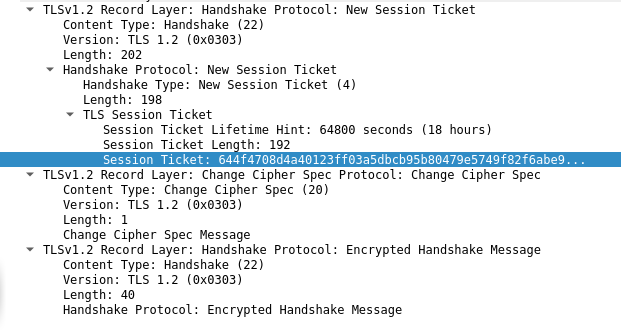
- On similar lines, server issues the client a Session Ticket which the client can then use to resume connections and not go through the entire Diffie Hellman procedure again (although it is valid only for 18 hours in our case). The server sends a Change Cipher Spec message, indicating that no more plaintext messages will be sent by the server. Lastly, the server sends its first encrypted message, an encrypted handshake, just like the client.
- That’s it. We have established a secure connection to a computer on the other side of the planet and verified its identity. Magic!
Crypto Primitives
Let’s discuss what goal of cryptography is achieved by what part of this entire handshake. Remember the cipher suite that the server choose? It was TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256.
ECDHE: ephemeral Elliptical Curve Diffie Hellman, as we saw, is used to establish a shared secret session key from the random values our client and the server exchanged (over an insecure channel). It is a key exchange crypto.
ECDSA: Elliptical Curve Digital Signature Algorithm is used to verify the public key supplied by the server, in our case nagekar.com, issued for Cloudflare by COMODO.
AES 128 with GCM: AES is a block cipher. Being a symmetric key encryption algorithm, it is much faster than the asymmetric key ones, and hence used for encryption of all the data after the initial handshake is done. 128 is the size of the key in bits, which is sufficiently secure. GCM stands for Galois/Counter Mode, which is an encryption mode used with AES to provide authentication and integrity along with the regular confidentiality.
SHA256: Since we’re using AES with GCM, we won’t be using this hash function for message authentication. However, since TLS 1.2, SHA256 is used as a PRF. It will also be used to verify that all content exchanged during the handshake were not tampered with.
Security Considerations
About trust: As you might have noticed, all the above steps were essentially so that two random computers can come up with a shared secret session key. The other part to this is Certificate Authorities. Why did we trust the certificate that the server sent us? Because it was signed by someone, whom we trusted. At the end of it all, you still have to implicitly trust someone to verify the identity. In this case, we’re trusting COMODO to have only signed one certificate for the domain in question.

About browser and updates: If you see the version of TLS that we used, it is 1.2 which is not the latest. The cipher suite is also not the best we could’ve got. Why did that happen? Simple, because we were using an outdated browser which didn’t support the strongest cipher suites and the latest version of TLS. Since that was a test machine, it doesn’t matter a lot. On any up to date browser, this is what you should see.

About cryptographic primitives: We saw some of the most understood crypto primitives being used in the handshake. This is a pattern you’ll see often while reading about cryptology. It is a sin to implement your own crypto, especially the primitives. Use a library that implements these primitives, or better yet, the entire cryptosystem.
About mathematics: The reason that we think the above scheme is secure, that no data is leaked even though key was generated using the information sent in clear, is because the basis of some of these cryptographic primitives are hard problems in mathematics. For example, since mathematicians believe that discrete logarithms are easy to verify but are hard to calculate the other way, we say that Diffie Hellman (which makes use of discrete logarithms) is secure. Similarly with RSA, mathematicians believe that factoring large prime numbers is a hard problem, hence RSA is considered secure as long as the numbers are large enough. Of course, not always is a mathematical proof available. For example, AES is considered secure, but there’s not proof that it is secure. We think it must be secure because the brightest minds in cryptology have spent thousands of man hours trying to break the encryption algorithm but they haven’t succeeded (yet?).
In Closing
As you can guess, a lot of important details are skipped in this article. There are two reasons for that. 1. I lack the necessary knowledge to simplify the deeper parts and 2. It would be boring to read if the post felt like a spec. If you wish to read more, refer to the list of references below this section.
References
Thank you for reading!