In this article, let’s look at some of the ways to do batch HTTP requests in Python and some of the tools at our disposal. Mainly, we’ll look at the following ways:
- Synchronous with
requestsmodule - Parallel with
multiprocessingmodule - Threaded with
threadingmodule - Event loop based with
asynciomodule
I was inspired to do this because I had a task at hand which required me to write code for a superset of this problem. As someone who can write basic Python, I implemented the most straightforward solution with for loops and requests module. The task was to perform HTTP HEAD requests on a bunch of URLs, around 20,000 of them. The goal was to figure out which of URLs are non-existent (404s, timeouts and so on) in a bunch of markdown files. Averaging a couple of URLs a second on my home network and my personal computer, it would’ve taken a good 3-5 hours.
I knew there had to be a better way. The search for one lead to me learning a few things and this blog post. So let’s get started with each solution. Do note that depending on the hardware and network, it might go up and down quite a bit, but what’s interesting is the relative improvements we make going from one method to the next.
Synchronous code with requests module
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import time
from helper.urls import urls
import requests
def make_request(url):
try:
res = requests.head(url, timeout=3)
print(res.status_code)
except Exception as e:
print(e.__class__.__name__)
def driver():
for url in urls:
make_request(url)
def main():
start = time.perf_counter()
driver()
end = time.perf_counter()
print(f'Synchronous: {end - start:.2f}')
if __name__ == '__main__':
main()
If you try to think what you’d do if you had to check 10 URLs if they work, and write that process down in pseudocode form, this approach is pretty much what you’d get. Single threaded and synchronous, just like a human.
This script fetches 800 random URLs from a different file, makes an HTTP HEAD request to each, and then times the whole operation using time.perf_counter().
I ran all the tests on a Raspberry Pi 3 running freshly installed Ubuntu 20.04 LTS, but I don’t intend on making this scientific or reproducible, so don’t take the results at face value and test it yourself. Better yet, correct me and tell me how I could’ve done it better!
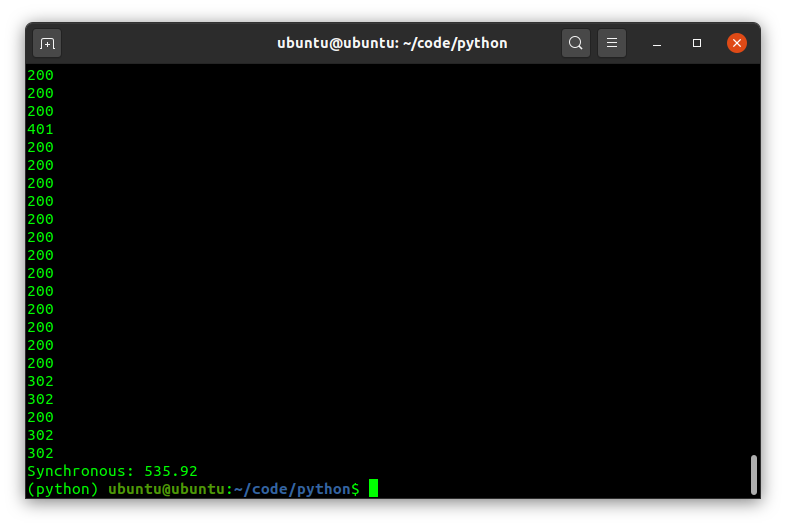
With that we have our baseline. 536 seconds for 800 URLs that we can use to compare our other methods against.
Multiprocessing with multiprocessing module
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import time
from helper.urls import urls
import requests
from multiprocessing import Pool
from multiprocessing import cpu_count
def make_request(url):
try:
res = requests.head(url, timeout=3)
print(res.status_code)
except Exception as e:
print(e.__class__.__name__)
def driver():
with Pool(cpu_count()) as p:
p.map(make_request, urls)
def main():
start = time.perf_counter()
driver()
end = time.perf_counter()
print(f'Multiprocessing: {end - start:.2f}')
if __name__ == '__main__':
main()
My Raspberry Pi is a quad core board, so it can have 4 processes running in parallel. Python conveniently provides us with a multiprocessing module that can help us do exactly that. Theoretically, we should see everything done in about 25% of the time (4x the processing power).
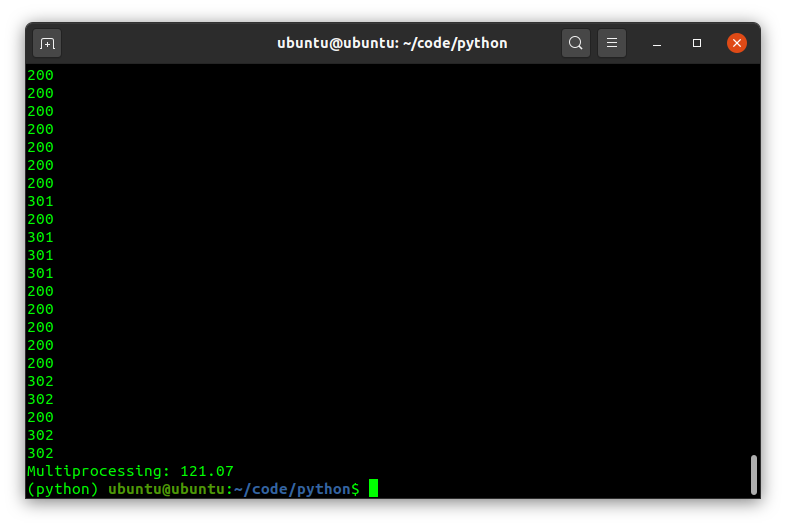
So a bit less than 25% but if I run both the scripts over and over again, the average converges to a ratio of roughly 4:1 as we’d expect.
Threading with threading module
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import time
from helper.urls import urls
import requests
import threading
def make_request(url):
try:
res = requests.head(url, timeout=3)
print(res.status_code)
except Exception as e:
print(e.__class__.__name__)
def driver():
threads = []
for url in urls:
t = threading.Thread(target=make_request, args=(url,))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
def main():
start = time.perf_counter()
driver()
end = time.perf_counter()
print(f'Threading: {end - start:.2f}')
if __name__ == '__main__':
main()
With threading, we essentially use just one process but offload the work to a number of thread that run concurrently (along with each other but not technically parallel).
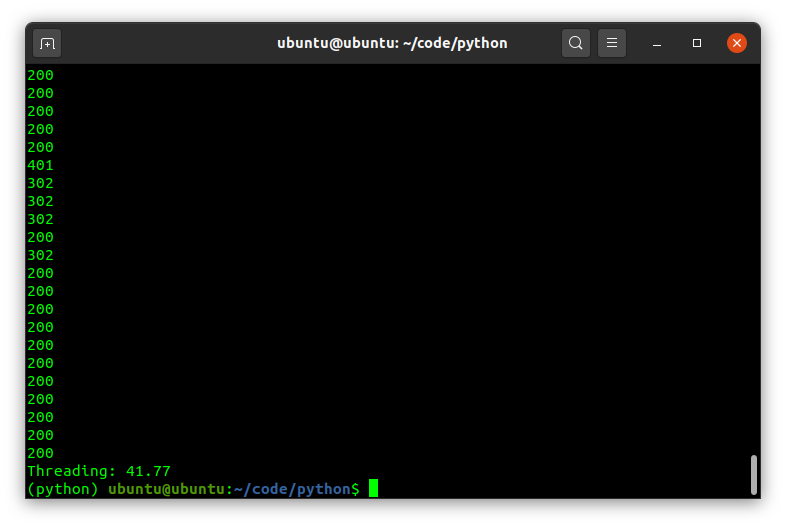
Threading runs much faster than the multiprocessing, but that’s expected as threading is the right tool for network and I/O bound workload while multiprocessing suits CPU intensive workloads better.
Short detour: visualizing threading and multiprocessing
If you look into your system monitor, or use htop like I have in the following images, you’ll see how multiprocessing differs from threading. On my dual core (with 4 threads) personal computer, multiprocessing creates four processes (with only the default one thread per process), while threading solution creates a much larger number of threads all spawned from one process.
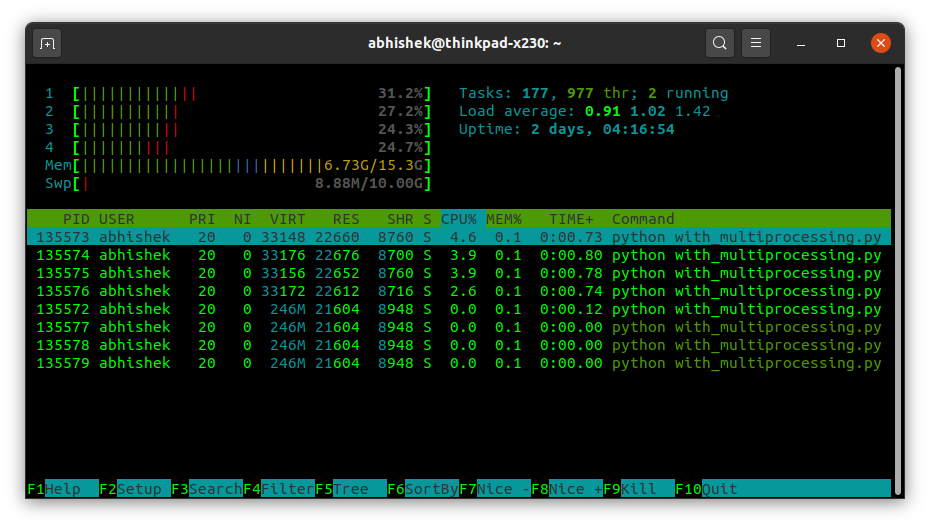
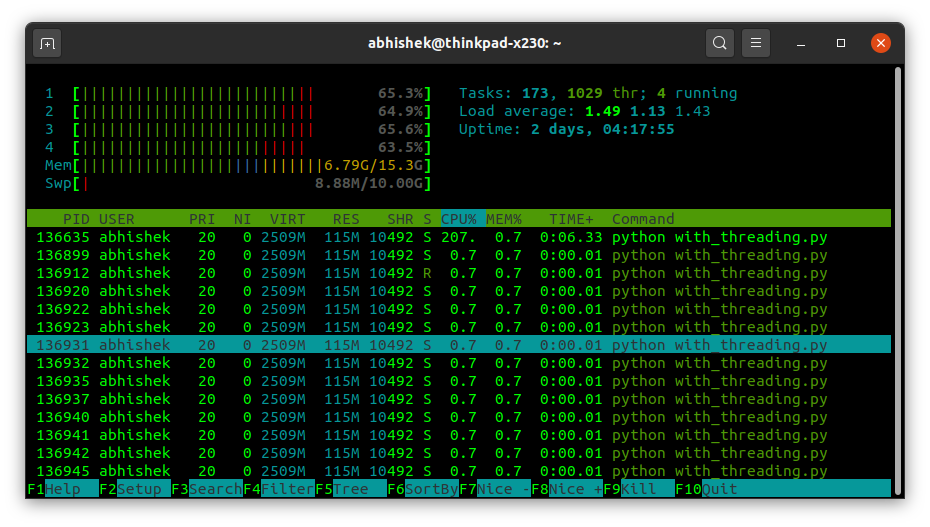
This helped me better understand the difference between threads and processes on a high level and why threading solution is much faster for this particular workload.
Asynchronous code with asyncio module
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import time
from helper.urls import urls
import httpx
import asyncio
async_client = httpx.AsyncClient()
async def make_request(url):
try:
res = await async_client.head(url, timeout=3)
print(res.status_code)
except Exception as e:
print(e.__class__.__name__)
async def driver():
await asyncio.gather(*[make_request(url) for url in urls])
def main():
start = time.perf_counter()
asyncio.run(driver())
end = time.perf_counter()
print(f'Async IO: {end - start:.2f}')
if __name__ == '__main__':
main()
Finally, we reach Async IO, sort of the right tool for the job given its event driven nature. It was also what sparked my curiosity in the subject in the first place as it is quite fascinating, coming from the event driven JavaScript land, to find an event loop in Python. [Read: Callbacks And Event Loop Explained and Event Driven Programming]
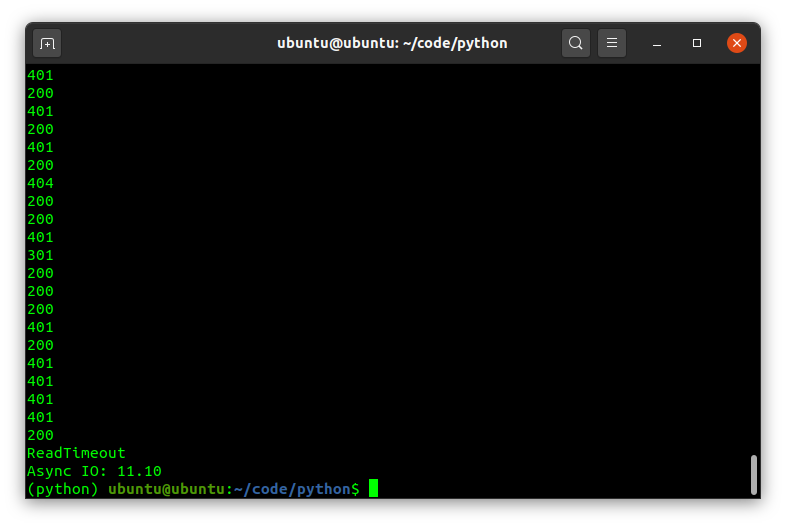
Clearly this task is made for this approach, and the code looks surprisingly simple to understand which is a plus.
In closing
That’s it for this little adventure in Python land I sincerely hope you enjoyed it. If you find any corrections and improvements in the above text, please write them to me. It will help me get better at Python (and writing )
Thank you for reading